Programmatic schema management
Create and update schemas through API workflows so model changes can be tracked and integrated into engineering delivery processes.
Feature
Automate schema creation, source provisioning, and deterministic regeneration with the Synthbrew API to support CI pipelines and repeatable environment setup.
Create and update schemas through API workflows so model changes can be tracked and integrated into engineering delivery processes.
Spin up new sources in a consistent way across projects, environments, or customer instances without manual dashboard setup.
Trigger deterministic regeneration in tests and release checks to keep validation repeatable and reduce environment drift.
Manual setup can slow teams down when multiple environments need consistent data infrastructure. Synthbrew API automation lets engineering teams create schemas, provision sources, and trigger regeneration through scripts and pipeline jobs.
This makes data setup predictable and easier to scale across development, staging, QA, and temporary review environments.
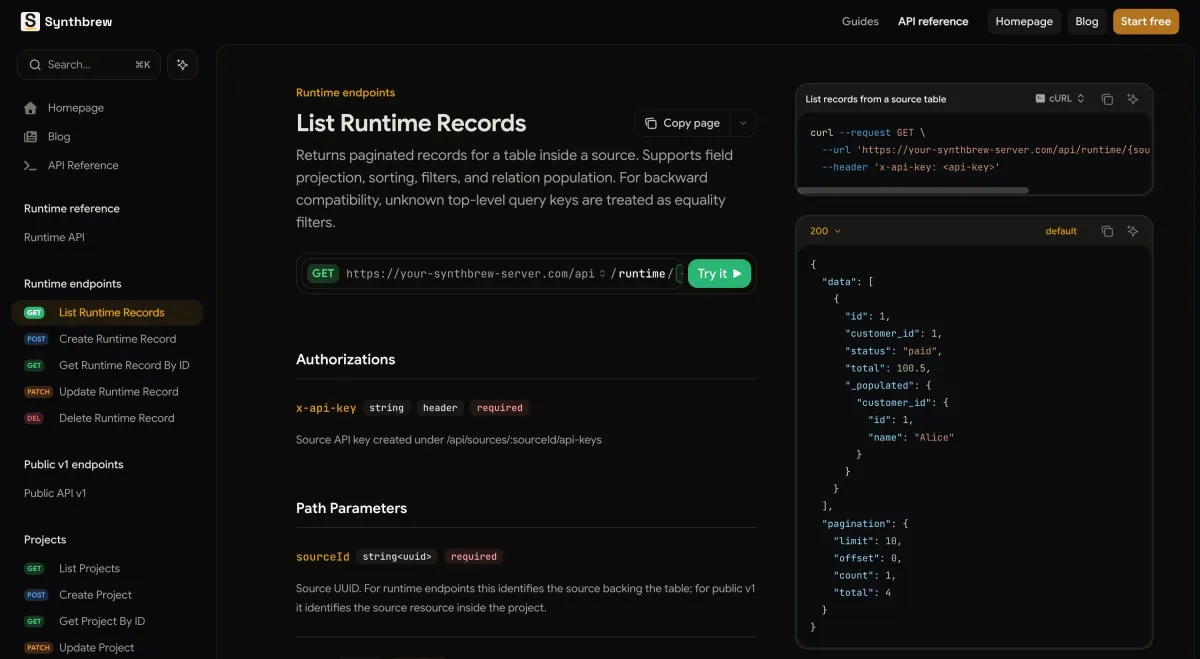
Defining schemas through API calls helps teams standardize how new projects are initialized. Instead of relying on one-off dashboard steps, schema setup can live in versioned automation that is easier to review and reuse.
This approach improves consistency across teams and reduces onboarding friction for new services.
When sources and data generation are automated, release processes become more reliable. Teams can spin up fresh environments, seed deterministic datasets, and validate application behavior with fewer manual tasks in the critical path.
It also enables faster teardown and recreation of environments when troubleshooting complex issues.
API-driven workflows reduce repetitive setup work, lower the risk of configuration drift, and make data infrastructure easier to scale as product complexity grows. Teams spend less time coordinating environment state and more time shipping validated functionality.
To understand how this pairs with runtime access and schema controls, review the full features overview and pricing options.
Use this playbook as your starting point, then compare other solution tracks or plan limits for your rollout.