Deterministic dataset regeneration
Use consistent seeds to recreate the same data patterns across development, QA, and staging whenever you need to validate behavior.
Feature
Generate reproducible relational datasets with deterministic seeds, configurable row distribution, and source-level controls for stable QA and frontend workflows.
Use consistent seeds to recreate the same data patterns across development, QA, and staging whenever you need to validate behavior.
Set row volume, locale, timezone, and per-entity distribution so each environment matches the conditions your product needs.
Keep scenarios repeatable for bug reproduction, regression checks, and stakeholder demos without rebuilding fixtures manually.
Seeded data generation gives product teams a practical way to reproduce conditions that matter. Instead of depending on stale fixture files or ad hoc scripts, you can regenerate structured relational data with the same seed and expect consistent behavior between runs.
This consistency becomes critical when frontend teams and QA engineers need to test edge cases more than once. By keeping data generation deterministic, teams can verify fixes confidently and reduce disagreements about whether a bug is truly resolved.
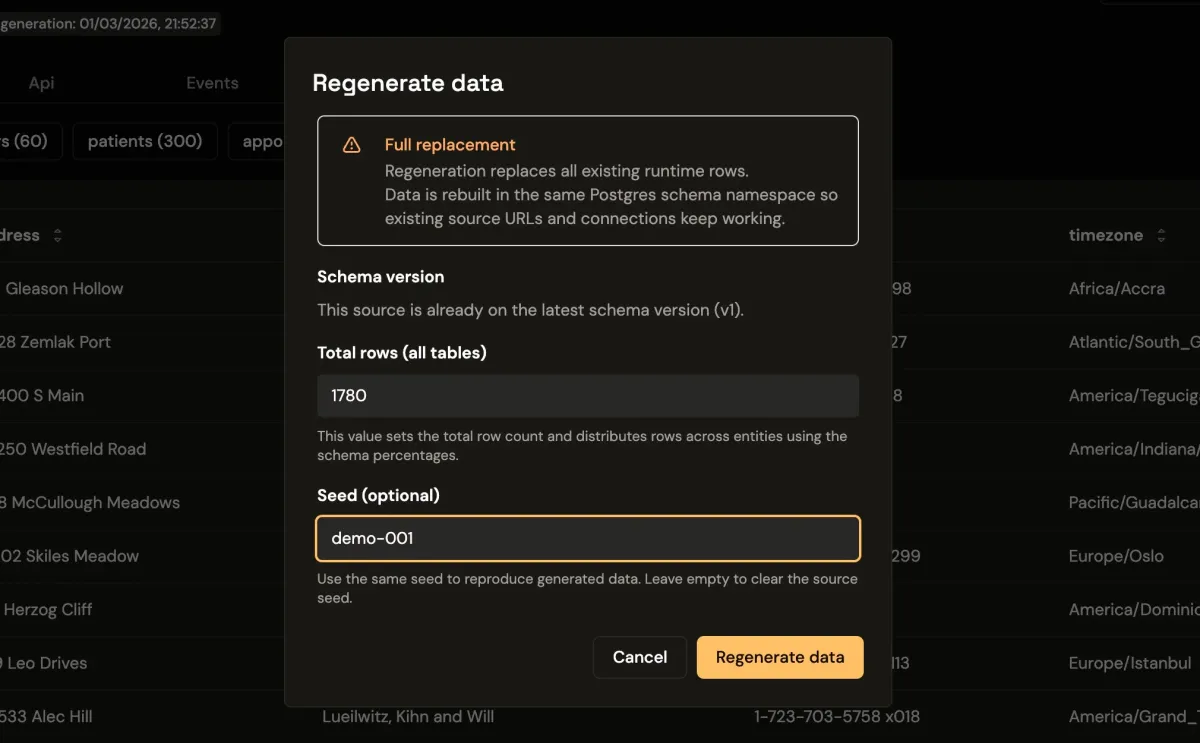
Real product behavior depends on more than record count alone. Regional formats, temporal values, and relationship density all influence how interfaces behave under realistic conditions. Seeded generation control allows each source to match these constraints so teams can validate workflows with data that resembles production.
Per-entity distribution also helps test parts of the product that rely on data skew, such as high-volume parent records, sparse child relationships, or mixed status states.
As products evolve, static datasets drift away from active schema changes and business logic. Controlled regeneration prevents this drift by rebuilding data against current schema versions while preserving deterministic patterns. QA can rerun scenarios quickly, and engineering can trace behavior changes back to explicit generation settings.
This approach supports faster release cycles because teams spend less time manually repairing fixtures and more time validating actual user flows.
When data can be regenerated predictably, frontend development, QA validation, and release checks all become more stable. Teams reduce rework, improve regression reliability, and move from fragile mock-heavy testing toward production-like confidence earlier in the delivery cycle.
To see how this fits with other capabilities, review the full features overview or compare environment limits on pricing.
Use this playbook as your starting point, then compare other solution tracks or plan limits for your rollout.