TL;DR
LLMs are great at designing structures and constraints, but poor at producing large datasets. Bulk output is expensive, inconsistent, and not referentially safe. A better architecture is to let AI generate schema and generation rules, then use a deterministic engine to create rows in a real database, expose a stable CRUD API, and regenerate the same world with a seed.
The tempting idea (and why it keeps coming up)
“Just ask ChatGPT to generate fake data” is one of those ideas that feels obvious at first. You get instant JSON or CSV, no backend setup, and a quick path to a demo.
The trap is that first success usually happens at small scale. A few dozen rows can look fine in a table. Problems start when you need thousands of records, relational consistency, and a dataset you can trust across charts, filters, drilldowns, and multiple screens.
The cost wall: tokens scale with rows
If you generate 10,000 rows directly from an LLM, output tokens become the bottleneck. Even compact JSON gets large quickly, and each retry multiplies cost and latency. Then you pay again for prompt iteration, formatting fixes, and re-runs when requirements change.
Back-of-napkin math makes this clear:
10,000 rows
x 10 columns
x ~12-20 chars/value
+ JSON keys, commas, quotes, braces
= a very large output payload (often hundreds of thousands of tokens)Compared with deterministic local generation, paying tokens for every row is usually the most expensive path.
The integrity wall: LLM output does not guarantee relational correctness
Large synthetic datasets break when foreign keys drift, enum values slip, duplicates appear, or constraints are violated in subtle ways. That is where dashboard trust collapses.
A common failure looks like this: invoices reference subscription_id values that do not exist in subscriptions, or reference subscriptions that are canceled when your metric expects active ones. Your “active subscription revenue” query returns nonsense, and teams debug UI code that was never the issue.
When joins fail, dashboards lie.
The determinism wall: you cannot regenerate the same world
Run the same prompt again and you usually get a different dataset. That is fine for brainstorming, but bad for development workflows.
QA cannot reliably reproduce bugs. Visual regression gets flaky. Sales demos change shape between runs. Product discussions drift because people are reacting to different worlds.
Determinism is not optional when teams share environments.
The format wall: AI output is brittle plumbing
Even when the content is “close enough,” structured output often needs cleanup. Escaping breaks, CSV quoting drifts, date formats vary, nullable fields change shape, and schema details shift between runs. Teams end up writing parsers, validators, and repair scripts just to make AI output usable.
That is engineering effort you could spend on product behavior.
The correct division of labor
The better pattern is not anti-AI. It is fit-for-purpose:
Use LLMs for:
- turning requirements into schema drafts
- proposing realistic distributions and correlations
- mapping domain language into tables and relationships
- generating generation rules and defaults
Use deterministic engines for:
- high-volume row generation
- constraint enforcement and referential integrity
- seeded reproducibility
- fast regeneration and controlled updates
This model keeps AI where it is strongest and keeps your data pipeline reliable at scale.
Prompt / requirements
-> AI drafts schema + generator config
-> Deterministic generator populates Postgres
-> Runtime CRUD API serves frontend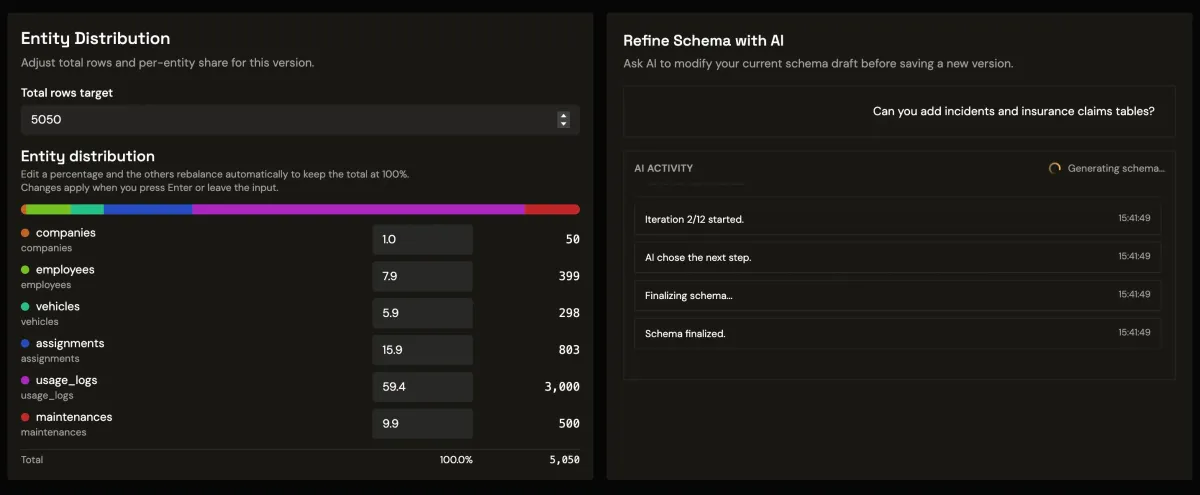
Bonus: time-evolving data is where row-by-row prompting gets worse
As soon as you need realistic changes over time, like churn curves, upgrades, refunds, and event growth across 30 to 90 days, text-output generation becomes even less practical. Deterministic engines can apply repeatable rules across time windows, while prompt-based row dumps tend to produce one-off snapshots.
For dashboards, continuity matters as much as row count.
Putting it into practice with Synthbrew
This is exactly the workflow Synthbrew is built around. You can prompt AI for schema and optional generation rules, publish immutable schema versions, create sources pinned to a specific version, and generate seeded relational data in Postgres-first workflows. Frontend apps integrate through runtime CRUD endpoints authenticated with source API keys via x-api-key.
When you need to reset an environment, regenerate with the same seed and configuration to get the same world back. That keeps demos stable, QA reproducible, and dashboard behavior credible.
GET /api/runtime/:sourceId/workspaces?limit=50&offset=0
x-api-key: sb_source_***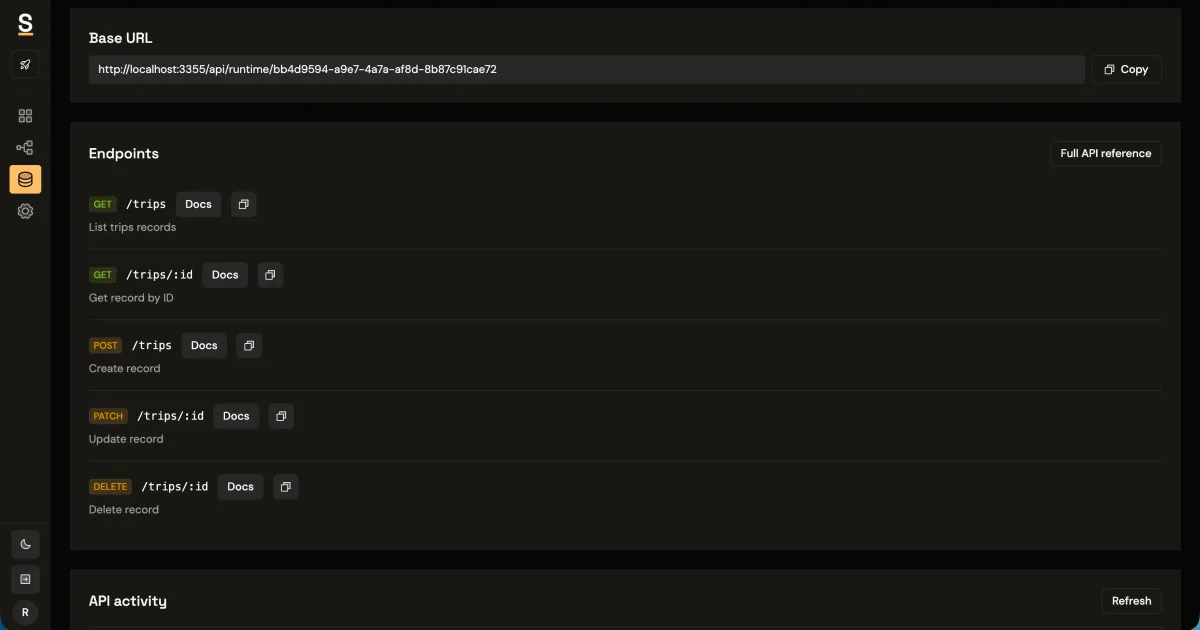
If you want implementation details, see AI and DB schema import, seeded generation control, runtime API key auth, and schema modeling with immutable versions.
Rule of thumb
Use AI to design the model. Use deterministic systems to produce the world.