TL;DR
If your UI is still simple, static JSON and request interception are fine. But once your app depends on shared state, joins, pagination, and time-based behavior, those mocks turn brittle fast. A better baseline is a real mock backend: a schema, a seeded database with relational fake data, and a CRUD API your frontend can call like production.
Frontend work gets blocked long before “backend done”
Most frontend teams hit the same wall in the middle of a sprint. The UI is coming together, routes exist, components look right, and then everything starts wobbling because the data underneath is too fake to trust.
You can usually ship the first screen with hand-written JSON. The second screen is where things get expensive. The list page needs filters and pagination, the detail page needs related records in tabs, and then someone adds a dashboard chart that aggregates by day and plan tier. Suddenly, your “temporary” mocks are carrying product logic they were never designed to carry.
A familiar demo-day failure looks like this: the chart query expects invoices tied to active subscriptions, but the fixture rows were generated independently, so relationships are broken and the graph comes back empty. The UI code might be correct, but the dataset is lying to you.
Why endpoint-level mocks stop working
There is nothing wrong with Mockaroo exports, Faker scripts, MSW, MirageJS, or JSON stubs in early prototyping. They are fast and useful. The problem is scope. They mock responses, not systems.
When your app is stateful across multiple screens, you need persistence, relational integrity, and consistency over time. Without those, teams spend energy debugging fake failures or patching fixtures instead of building product behavior. This is why dashboard demo data is especially painful with flat mocks: charts, drilldowns, and filters only feel real when the underlying model is coherent.
Use static mocks for isolated components and marketing pages. Use a system-level mock when your UI flow depends on joins, mutations, and history.
The minimum viable mock backend
You do not need a full backend team to get production-like behavior, but you do need a minimum stack. In practice, the bar is simple: data should persist, relations should be valid, generation should be deterministic, and frontend calls should go through a stable API.
Seed + schema version + generator config = reproducible dataset.
Frontend app
-> CRUD API
-> Postgres source (seeded relational dataset)That’s the core. Everything else is optional.
Start with an 80/20 schema your team already understands
For a first pass, pick a domain everyone on the team can reason about quickly. SaaS billing works well because it gives you users, workspaces, subscriptions, invoices, and event timelines in one model. You get enough complexity to test real UI flows without modeling an entire business.
Here is a compact SQL starting point:
create table workspaces (
id uuid primary key,
name text not null,
plan text not null,
created_at timestamptz not null default now()
);
create table subscriptions (
id uuid primary key,
workspace_id uuid not null references workspaces(id),
status text not null,
started_at date not null,
canceled_at date
);
create table invoices (
id uuid primary key,
subscription_id uuid not null references subscriptions(id),
amount_cents integer not null,
currency text not null default 'USD',
issued_at date not null,
refunded_at date
);
create index idx_subscriptions_workspace_id on subscriptions(workspace_id);
create index idx_invoices_subscription_id on invoices(subscription_id);
create index idx_invoices_issued_at on invoices(issued_at);This tiny model is enough to validate list pages, detail tabs, billing history, and plan analytics. If those flows work here, you have a credible foundation.
To make dashboards feel real, shape your generator like production traffic: maybe 80% of workspaces on free plans with a long tail on enterprise, higher churn for trial/free cohorts than annual ones, and invoices naturally clustered near month boundaries.
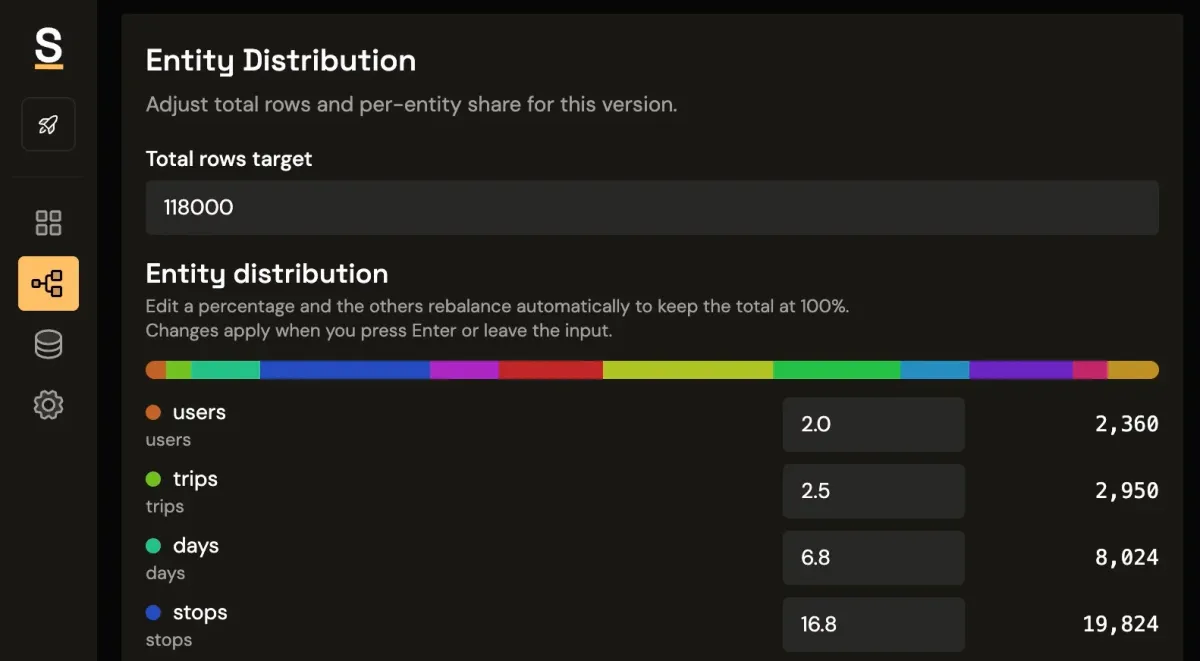
Determinism is what makes seeded data useful
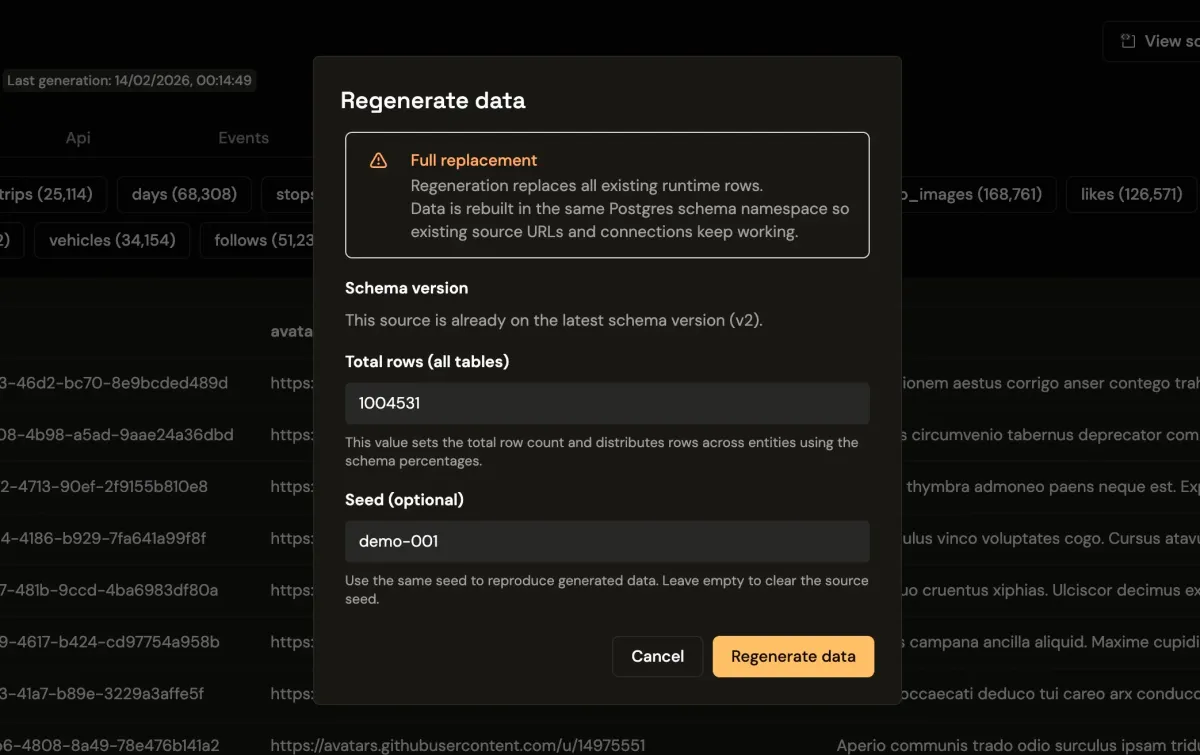
A seeded database is not just about generating records quickly. The value is regeneration. If your seed and generation settings are fixed, you can recreate the same data shape on demand across local, QA, and preview environments. This is where Seeded Generation Control helps teams keep behavior repeatable.
That stability matters for snapshot tests and visual regression checks. It also matters in debugging. When QA reports that churn charts spike after a change, engineering can regenerate the same dataset and reproduce the issue instead of arguing about whether fixtures drifted.
For Postgres mock data, deterministic generation is the difference between a one-time demo and a repeatable workflow.
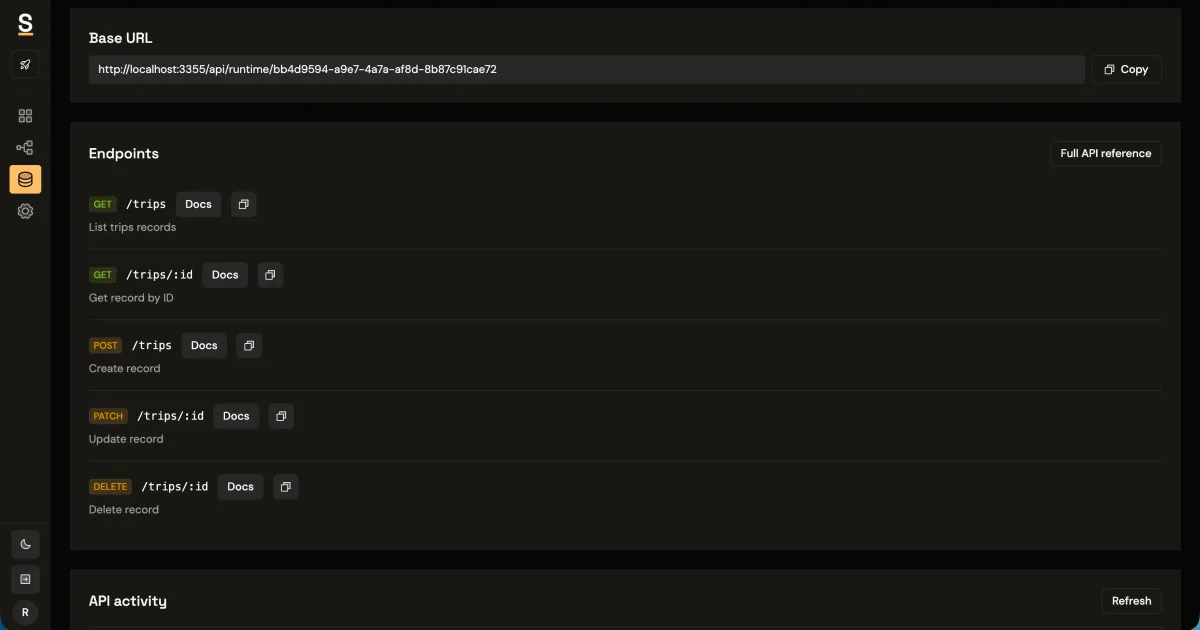
The CRUD surface your frontend actually needs
Most product UIs do not need dozens of endpoints to unblock. They need a predictable set of reads and writes that support table views, detail views, and basic mutations.
GET /workspaces?limit=50&offset=0&plan=pro
GET /workspaces/:id
POST /subscriptions
PATCH /subscriptions/:id
DELETE /invoices/:id
GET /events?from=2026-01-01&to=2026-02-01&workspaceId=550e8400-e29b-41d4-a716-446655440000From the frontend side, the integration should feel unremarkable:
const response = await fetch(
`${RUNTIME_API_HOST}/workspaces?limit=50&offset=0&plan=pro`,
{ headers: { "x-api-key": runtimeKey } }
);
const { data } = await response.json();For app-plane auth in Synthbrew, the dashboard session is cookie-based (httpOnly), so frontend fetch calls should use credentials: "include" instead of sending a Bearer token manually.
If your mock environment supports stable pagination, server-side filters, and date range queries, your frontend behavior will be much closer to production before the real backend lands.
If you want request and response details for those patterns, the runtime API docs and quickstart are good references while wiring frontend calls.
Separate environments are not optional for serious demos
Teams often discover this late. The same dataset cannot serve every purpose. Sales needs polished numbers for a story, product needs messy edge cases, and QA needs deterministic reruns. If all of that happens in one shared environment, people step on each other.
A healthier pattern is one schema with multiple sources, each isolated for a goal. The model stays consistent while the data context changes. That lets you run client demos, preview environments, and internal testing without cross-contamination, especially when you keep schema evolution explicit with versioned modeling.
Putting this together with Synthbrew
In Synthbrew, the workflow is straightforward: define your schema in SQL, a visual builder, or an AI prompt; create a source for the environment you need; let the platform generate seeded relational data; and connect your app through the runtime CRUD API or source-level Postgres access.
Because the schema and source are explicit objects, regeneration is controlled instead of ad hoc. You can keep one version for product demos, another for QA, and reset either one without hand-editing fixtures. That is usually the point where frontend teams stop treating mocks as throwaway artifacts and start treating them as delivery infrastructure.
When not to do this
If you are building a one-off component demo, a static marketing page, or a pure design prototype with no data relationships, this setup is overkill. The goal is not to replace lightweight mocks everywhere. The goal is to use the right level of realism when your UI depends on system behavior.
The simple rule
When your frontend relies on joins, filters, and time-series behavior, stop mocking endpoints and start mocking the system.